Kubernetes: weave picked the public IP on one of the worker nodes
I have a 2 master and 2 worker kubernetes cluster. Each node has private IP in the range 192.168.5.X and public IP. After creating the weave daemonset, the weave pod picked the correct internal IP on one node but on the other node it picked the public IP. Is there any way we can instruct weave pod to pick the private IP on the node?
Im creating the cluster from scratch by doing everything manually on the VMs created on Virtual Box on local laptop. I refer the below link
https://github.com/mmumshad/kubernetes-the-hard-way
After deploying weave pods on worker node, weave pod on one of the worker nodes uses the NAT ip as below.
10.0.2.15 is the NAT IP and 192.168.5.12 is internal IP
kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
weave-net-p4czj 2/2 Running 2 26h 192.168.5.12 worker1 <none> <none>
weave-net-pbb86 2/2 Running 8 25h 10.0.2.15 worker2 <none> <none>[@master1 ~]$ kubectl describe node
Name: worker1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=worker1
Annotations: node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Tue, 10 Dec 2019 02:07:09 -0500
Taints: <none>
Unschedulable: false
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 11 Dec 2019 04:50:15 -0500 Wed, 11 Dec 2019 04:50:15 -0500 WeaveIsUp Weave pod has set this
MemoryPressure False Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 02:09:09 -0500 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 02:09:09 -0500 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 02:09:09 -0500 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 04:16:26 -0500 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 192.168.5.12
Hostname: worker1
Capacity:
cpu: 1
ephemeral-storage: 14078Mi
hugepages-2Mi: 0
memory: 499552Ki
pods: 110
Allocatable:
cpu: 1
ephemeral-storage: 13285667614
hugepages-2Mi: 0
memory: 397152Ki
pods: 110
System Info:
Machine ID: 455146bc2c2f478a859bf39ac2641d79
System UUID: D4C6F432-3C7F-4D27-A21B-D78A0D732FB6
Boot ID: 25160713-e53e-4a9f-b1f5-eec018996161
Kernel Version: 4.4.206-1.el7.elrepo.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://18.6.3
Kubelet Version: v1.13.0
Kube-Proxy Version: v1.13.0
Non-terminated Pods: (2 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default ng1-6677cd8f9-hws8n 0 (0%) 0 (0%) 0 (0%) 0 (0%) 26h
kube-system weave-net-p4czj 20m (2%) 0 (0%) 0 (0%) 0 (0%) 26h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 20m (2%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
Events: <none>
Name: worker2
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=worker2
Annotations: node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Tue, 10 Dec 2019 03:14:01 -0500
Taints: <none>
Unschedulable: false
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 11 Dec 2019 04:50:32 -0500 Wed, 11 Dec 2019 04:50:32 -0500 WeaveIsUp Weave pod has set this
MemoryPressure False Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 03:14:03 -0500 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 03:14:03 -0500 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 03:14:03 -0500 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 11 Dec 2019 07:13:43 -0500 Tue, 10 Dec 2019 03:56:47 -0500 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 10.0.2.15
Hostname: worker2
Capacity:
cpu: 1
ephemeral-storage: 14078Mi
hugepages-2Mi: 0
memory: 499552Ki
pods: 110
Allocatable:
cpu: 1
ephemeral-storage: 13285667614
hugepages-2Mi: 0
memory: 397152Ki
pods: 110
System Info:
Machine ID: 455146bc2c2f478a859bf39ac2641d79
System UUID: 68F543D7-EDBF-4AF6-8354-A99D96D994EF
Boot ID: 5775abf1-97dc-411f-a5a0-67f51cc8daf3
Kernel Version: 4.4.206-1.el7.elrepo.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://18.6.3
Kubelet Version: v1.13.0
Kube-Proxy Version: v1.13.0
Non-terminated Pods: (2 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default ng2-569d45c6b5-ppkwg 0 (0%) 0 (0%) 0 (0%) 0 (0%) 26h
kube-system weave-net-pbb86 20m (2%) 0 (0%) 0 (0%) 0 (0%) 26h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 20m (2%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
Events: <none>Similar Questions
1 Answer
I can see that you have different IPs not only in your pods, but also in your nodes.
As you can see in the kubectl describe node output InternalIP for worker1 is 192.168.5.12 and for worker2 is 10.0.2.15.
This is not expected behavior, so it's important to make sure you have attached both of your VirtualBox VMs to the same adapter type.
Both should be in the same network and in the comments you confirmed that this was the case and that explains this behavior.
Here is an example of that configuration:
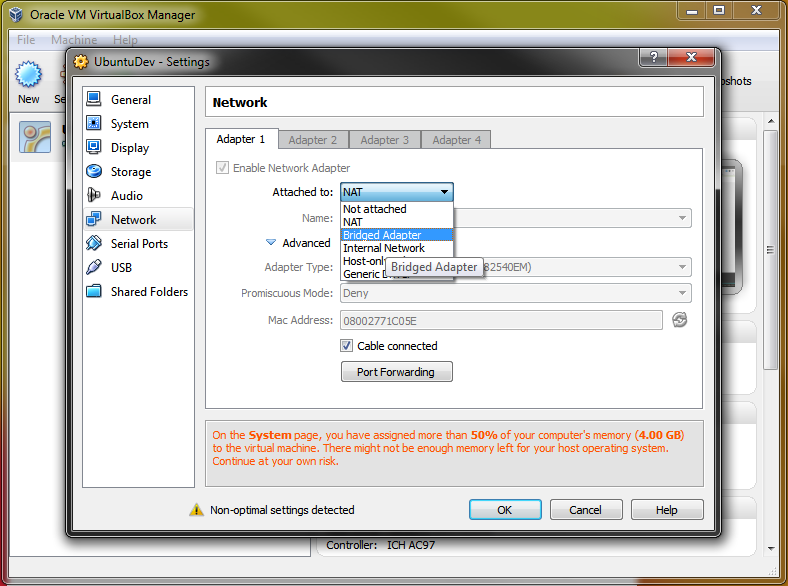
As you mentioned on comments, the first node was added manually and the second was added during the TLS bootstraping and it got added even with "wrong" IP Address.
To solve this issue the best thing you can do is to bootstrap you cluster from scratch again using the same Adapter Settings on Virtual Box for all nodes.